Designing AI for Disruptive Science
Words by
Alvin Djajadikerta

In On Exactitude in Science, the writer Jorge Luis Borges imagines an empire so devoted to cartography that its mapmakers draw a map as large and detailed as the empire itself. “In the Deserts of the West, still today, there are Tattered Ruins of that Map,” Borges writes, “inhabited by Animals and Beggars.” Borges’s map is a parable for knowledge, and one of its lessons is that too much detail can quickly become impractical — a map at that scale would be perfect but useless.
But with today’s AI systems, one might wonder if such a map is so absurd after all. Computers and the Internet have already helped us to digitize much of human knowledge, and AI enables us to scan it quickly and easily. For instance, large language models are trained on trillions of words spanning much of recorded human knowledge. In biology, systems like AlphaFold learn from large databases to predict a protein’s folded structure from its amino acid sequence.
This means that, in some domains, something resembling Borges’s life-sized map has become extremely useful. And given the rate of progress on this front, it may seem like advancing science now simply requires building ever larger and more navigable versions of such AI systems, effectively mapping every field.
A lack of practicality, however, was never the sole flaw of Borges’s map. The deeper problem is that adding detail only gives you more of the same kind of information — more roads, more mountains, more villages — when what you might need is a completely different schematic.
Consider the map of the London Underground. Until 1933, the map plotted stations at geographically accurate locations in London. But this made central London, where most stations clustered, an unreadable tangle, while the outer suburbs, devoid of relevant data, took up most of the space. The draughtsman Harry Beck solved this inefficiency by abandoning geographic accuracy and instead redrawing the network as a circuit diagram of colored lines and evenly spaced stations.

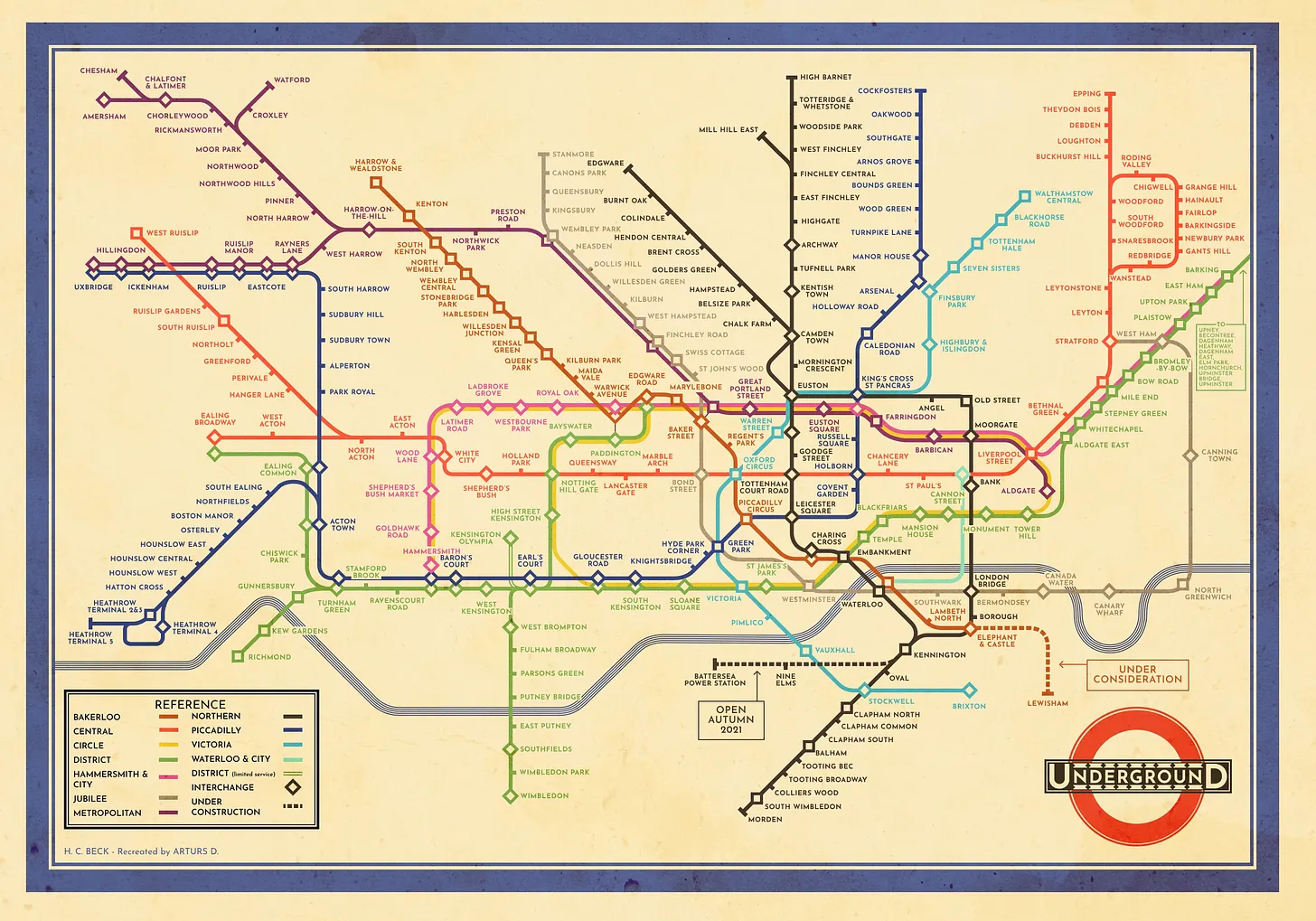
A scientific paradigm can also be thought of as a kind of map, but unlike Beck, scientists do not usually know in advance what their maps will be used for. Instead, new paradigms are driven by the desire to explain complex phenomena with a simple and unified set of principles. Such principles tend to have knock-on implications that stretch far beyond the phenomena that inspired them.
For instance, by the mid-nineteenth century, electricity and magnetism were described by a patchwork of separately discovered laws, each explaining a different phenomenon. The physicist James Clerk Maxwell simplified the field by replacing this patchwork with four short equations. But they also implied the existence of electromagnetic waves that could travel through space, including low-frequency waves no one had yet detected. These waves eventually became the basis for radio.
Current AI, by contrast, is not set up to do this. It excels at prediction within existing frameworks, but paradigm shifts require replacing these with simpler alternatives whose implications haven’t yet been explored. A computational system trained on electromagnetic measurements may have predicted these results perfectly, but would never have found radio.
Seen in that light, even as AI becomes more central to scientific work, we risk falling into what one might call hypernormal science, where we get ever better at prediction within current models, alongside a weakening capacity to ask completely new categories of questions. Much like Borges’s empire of cartographers, we risk confusing more detail for a true understanding of the territory.
To avoid this kind of myopia, we must deliberately build AI that helps us devise new conceptual vocabularies. In other words, we must build visionary machines rather than merely predictive ones.
{{signup}}
Before exploring how to build such visionary AI, it helps to look more closely at how paradigm shifts in science actually happen. Science usually progresses by adding facts within an existing paradigm, which functions like a rulebook for a field. But over time, evidence accumulates that an existing paradigm cannot explain, requiring a new one.
One might expect that a new paradigm would immediately replace the old one as it better explains the facts. Instead, they tend to gain preeminence only after becoming useful for new applications.
One example is the development of special relativity. In the late nineteenth century, physicists could describe light with wave equations. Because every familiar wave (like sound or water) seemed to need a material carrier, the scientific consensus was that light must also travel through an invisible medium, dubbed the luminiferous ether. The academic establishment was profoundly attached to this concept; Lord Kelvin, the elder statesman of British physics, even declared the ether was the only thing in physics we could be absolutely certain existed.
Albert A. Michelson and Edward W. Morley reasoned that if the ether existed, the Earth’s motion would create an “ether wind,” making light traveling along that wind move at a slightly different effective speed than light traveling across it. Michelson and Morley sent light along two perpendicular paths and expected that because of this speed difference, one beam would come back slightly later than the other. But their experiment revealed no detectable difference.

This result didn’t immediately convince the academic community to abandon the concept of ether. Many physicists (including Michelson) instead adopted an interim position, that the ether’s effects must be hidden in some way. Most prominently, Hendrik Lorentz proposed that the ether existed, but that objects moving through it would shorten in the direction of travel, canceling the expected signal.
An alternative paradigm was ultimately offered by Albert Einstein, then a 26-year-old patent clerk in Bern, Switzerland. His theory of special relativity posited two principles: that the laws of physics are the same in every uniformly moving frame, and the speed of light in a vacuum is the same for all such observers. Through these principles, Einstein was attempting to introduce “a simple and consistent theory,” by which “the introduction of a ‘luminiferous ether’ will prove to be superfluous.”
Initially, Lorentz’s and Einstein’s theories both explained the known experimental data similarly well. But Einstein’s theory proved far more fruitful over time. If light’s speed were genuinely constant, then space and time could not be absolute. This eventually led to the demonstration that mass and energy had to be equivalent, as per Einstein’s famous equation, E=mc², which now underpins technologies from nuclear power to medical imaging.
A paradigm can take hold even if incomplete, provided its core idea is sufficiently useful. For instance, Charles Darwin’s theory of natural selection offered a single principle that could explain the diversity of living species even though it still lacked an explanation for how traits actually passed from parent to offspring. In the late 1860s, he posited the missing mechanism, the erroneous notion of “pangenesis.” In it, he speculated that every cell in the body sheds tiny particles called “gemmules” that collect in the reproductive organs and transmit traits to offspring. Despite this error, Darwin’s core vision survived, and spread amongst biologists, before genetics supplied the necessary, physical mechanisms.
Thus, Einstein and Darwin were both able to generate simple and elegant theories that could make predictions beyond current evidence, even when some details were missing or wrong. In both cases, their decisive advantage was not technical skill within the paradigm, but rather a willingness to step outside it: Einstein benefited from being an outsider to the academic establishment, as this freed him from attachment to the idea of the ether,1 while Darwin appropriated concepts from Charles Lyell’s geology and resource competition from Thomas Malthus’s economics.
If paradigm shifts require stepping outside the prevailing logic, we should ask whether current AI is set up to do this.
Consider an early attempt. In the late 1970s, computer scientist Douglas Lenat built the Automated Mathematician, a program designed to discover not just new facts but entire mathematical concepts. It would start with simple ideas, combine and vary them, and keep the results that seemed interesting. It appeared to work, reportedly rediscovering prime numbers and Goldbach’s conjecture. But its creativity turned out to be limited, because many of the concepts it “discovered” were already implicit in the way mathematics was written inside the program.
While today’s AI has vastly more power than the Automated Mathematician, a similar constraint applies. Most machine-learning systems are trained by minimizing prediction error against a dataset whose inputs and labels are defined in advance. This makes them very good at predicting current data, but locks them into the conceptual vocabulary of the data they learn from.
Consider medicine before germ theory. In the mid-nineteenth century, doctors thought that illness was caused by noxious air, and kept meticulous records accordingly. The physician William Farr mapped cholera deaths across London and found they correlated strongly with low elevation, which he thought was because noxious vapors accumulated in low-lying areas. He was actually picking up a real signal: low-lying districts were closer to the contaminated Thames River. But because his data was organized around air quality, he could not find the true cause.
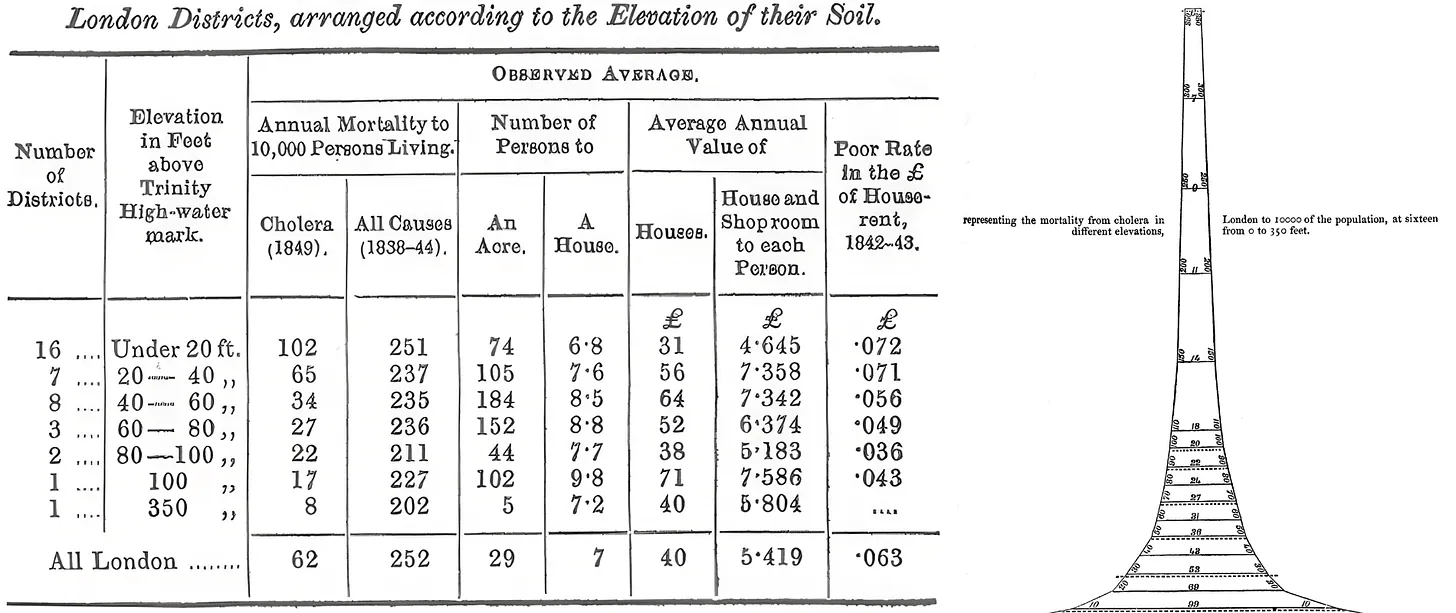
An AI trained on Farr’s records could have found even subtler correlations, and would have been genuinely useful for predicting which neighborhoods would be hit hardest in the next outbreak. But it would not be able to derive the concept of a waterborne microorganism, as this was not a variable anyone had yet recorded. It took researchers like Louis Pasteur and Robert Koch, working with microscopes and culture dishes rather than statistical registers, to establish germ theory and open the door to antibiotics, antiseptic surgery, and modern public health.
In 2023, Google DeepMind used a graph neural network called GNoME to predict the stability of crystal structures at an enormous scale, discovering 2.2 million new materials. But the vast majority were substitutions within already-known structure types, for instance swapping one element for a neighboring one on the periodic table. The system optimized impressively for thermodynamic stability relative to known structures, but could not venture far from these.
Some newer AI models, known as foundation models, sidestep this problem partly by learning directly from raw data rather than human-curated labels. For instance, the protein generation model ESM3 was trained on protein sequences and structures, and managed to design a novel fluorescent protein highly different from those found in nature.
While impressive, generating novel proteins in this way is analogous to filling in unexplored spaces on a map, but not to creating new maps entirely. ESM3 does not, for instance, ask whether an amino acid sequence is the right level of description, or whether some other organizing principle might unify protein behavior with phenomena outside biology.
When researchers trained a foundation model on ten million simulated solar systems, it learned to predict planetary orbits with high accuracy, but acquired no representation of gravity. Instead, it had assembled a patchwork of statistical regularities that happened to produce correct trajectories. Of course, it is possible that such models already contain, buried in their weights, patterns that point beyond current theories; but extracting them would require deliberate study in its own right.
This grows in importance as scientists use AI more often in their work. On the far end of this spectrum, researchers have begun to develop “AI scientists,” end-to-end pipelines that aim to execute the whole scientific workflow by chaining together literature search, idea generation, code writing, experiment execution, and paper drafting. If these systems are successful, they might be able to work much faster than human scientists, and thereby may constitute the majority of scientific work that gets done.
But these systems have to evaluate the quality of the new ideas they generate, and it is hard to do so without reference to the existing paradigm. When the system proposes a new hypothesis or experiment, the only available proxy for what constitutes a good idea is consistency with existing science. This often involves passing simulated peer review, aligning with established results, and looking like a plausible contribution to the field. A genuinely novel reframing would likely score poorly on all of these measures, for the same reasons that paradigm-shifting work has always faced resistance from reviewers trained in the paradigm it aims to replace.
Simply put, optimizing performance on extant benchmarks makes it difficult for alternatives to emerge. And this, in turn, risks hypernormal science.
Consider a thought experiment in genetics. For centuries, breeders kept detailed records of which animals were mated, what their offspring looked like, and which traits appeared in which family lines. An AI trained on such data could learn to predict what size, color, or yield the offspring of any given two parents might have, which would surely prove immensely useful.
But such a predictor would never discover the gene as a discrete unit of inheritance, nor DNA as its carrier. Without that insight, while farmers may have been thrilled with their better breeding predictions, we would not have had the ability to create genetically modified organisms or targeted gene therapies. Indeed, a prolonged state of hypernormal science is dangerous precisely because its practical implications would not be immediately obvious.
There are early indications that this is already happening. A recent study of 41 million research papers found that scientists using AI publish more and receive more citations, but collectively, AI-augmented research covers around five percent less topical ground. This appears to be because AI gravitates toward problems rich in existing data, where the current paradigm is most established. The result is that AI induces authors to converge on known solutions, rather than search for new ones.
In a 2019 essay entitled The Bitter Lesson, the computer scientist Richard Sutton observed that methods which try to build in human knowledge consistently lose out, over time, to methods that simply scale search and learning. “We want AI agents that can discover like we can,” he writes, “not which contain what we have discovered.” This applies naturally to paradigm shifts, which by definition move beyond existing knowledge. It might seem, then, that the path to paradigm-shifting AI is to get out of the way and let computation run.
Indeed, open-ended systems like AlphaZero (which learned chess entirely through self-play) are capable of creating both powerful and highly original results. Starting from nothing but the rules, it played millions of games against itself, generating strategies and discarding the ones that lost. Within a day, it was playing at a superhuman level, and did so while playing extremely original moves. The grandmaster Peter Heine Nielsen compared it to a superior species landing on Earth and showing us how to play chess.
Science might seem like a more complex version of the same problem, requiring more powerful computation to solve. In some senses, though, the opposite is true. Chess has simple rules, but a winning strategy is extraordinarily complex. In science, the winning paradigms can be extraordinarily simple; special relativity only has two postulates. But without the benefit of hindsight, there is no clear way to pick a winning paradigm.
To design AI for disruptive science, we would need to understand what “rules” make one paradigm better than another, and build systems that optimize for these. This turns out to be a harder problem than scaling compute. The answer cannot simply be experimental success, since experiments are slow and do not always reliably distinguish between paradigms (as was the case with Lorentz and Einstein). And there are other plausible candidates, but none yet offer a sufficient formulation.
One rule might be that good paradigms are simple. There are early attempts to make AI optimize for this. For example, in physics, symbolic regression systems such as AI Feynman try to discover the simplest equation that explains the data, instead of doing a black-box mapping. On benchmarks drawn from the Feynman Lectures, the method discovered all 100 test equations, while prior software found only 71. One can even formalize a drive towards simple theories using the Minimum Description Length principle, which effectively penalizes unnecessary complexity.2
But these systems currently work on clean data with pre-selected variables, and only search one dataset at a time. So far, they have been tested on rediscovering equations we already know, but haven’t yet demonstrated that they can find new ones.
Another rule may be that good paradigms draw effective analogies. Feynman devoted a chapter of his Lectures to the observation that heat flow, fluid flow, diffusion, and electrostatics all share the same equations, treating this as a deep fact about nature. This makes intuitive sense: an idea that already works in two domains has a better chance of working in a third.
The most obvious kind of analogy is across disciplines, as when Darwin borrowed the logic of competitive scarcity from economics and applied it to biology. In principle, AI could search for these connections at a scale no individual researcher could match, trawling across fields for ideas that seem structurally similar. Early systems have been built that find functional analogies across large databases of patents and product descriptions.
But some analogies are not between written theories, but rather between an idea and a sensory intuition. At sixteen, Einstein imagined riding alongside a beam of light and asked what he would see. Maxwell’s equations modelled light as a wave. But if this were true, if one travelled at the speed of light, the wave would appear frozen, hanging motionless in space. To Einstein, this picture felt physically wrong; this visceral discomfort ultimately inspired him to develop special relativity.3
Some research programs are trying to ground AI reasoning in physical experience. There are early attempts at multimodal architectures that can jointly process vision, language, and action. Self-driving laboratories couple AI to robotic instruments that manipulate real materials, which could in principle ground abstract reasoning in physical feedback (though most operate within a single experimental domain). But these are early efforts, and the gap between a robotic arm pipetting reagents and multisensory human experience is vast.
In the meantime, the fastest path to getting effective analogies may be leveraging both human and AI abilities together. Humans have breadth across modes — we see, hear, touch, move through space, and read, all at once — which grounds our capacity for structural analogy. AI has depth within modes, having processed far more than any person ever could. If AI can help researchers learn faster across disciplinary boundaries, perhaps by disciplined use of LLMs, that alone could accelerate discovery.
The deeper problem is that we do not have a good formal understanding of how paradigm shifts actually happen. Simplicity and analogy alone do not appear to be a complete description. J.J. Thomson’s “plum pudding” model imagined atoms as spheres of positive charge with electrons scattered through them. It was simple, matched what was known at the time, and was comically analogical, but soon proved completely wrong.
For now, then, the Bitter Lesson for Science may be that scientific acceleration will not happen by default until we understand science itself better.4 But if we can identify the conditions that produce paradigm shifts, we can start to engineer them.
Understanding and codifying science is no small task. Since Bacon’s Novum Organum in 1620, we have had a reasonable account of how science works in theory — observe, form hypotheses, test, and revise. But paradigm shifts seem to depend just as much on conditions as on method: who gets to do science, what they are rewarded for, and how freely ideas can cross between fields, for instance.
We can learn some things from history. Bell Labs, Xerox PARC, and the early Laboratory of Molecular Biology at Cambridge all produced extraordinary concentrations of paradigm-shifting work, mostly because they were small groups with enough institutional protection to pursue ideas that looked unproductive by conventional measures. There are clear parallels, in fact, to the kind of independent self-play that made AlphaZero successful. But there are limited numbers of historical paradigm shifts to study, and we have barely begun to explore the design space.

Here, AI itself may be able to help. We have never been able to run controlled experiments on scientific institutions; it is impossible to create labs that differ in only one respect and compare the results. But we could run AI agents in parallel populations under different research conditions, and analyze the results in detail. In this sense, AI scientists may give metascience its first model organism.
For instance, one could test how group structure shapes discovery: do small, isolated teams produce more conceptual reorganization than large, well-connected ones? Do flat hierarchies outperform rigid ones? One could run AI agent populations that vary these factors independently and measure the results — something that is impractical to do with real institutions, where size, hierarchy, and communication patterns are all entangled.
Some of the optimism around AI for science rests on the intuition that if we build systems with much stronger general reasoning, discovery will follow as a near-automatic consequence. But there is no guarantee that this will happen by default. Many technologies have promised radical scientific acceleration, and so far, not completely fulfilled their promise.
The Internet, for example, made knowledge much easier to search, and in theory may have led to much faster science. Online collaboration has certainly sometimes enabled better scientific work, such as in the Polymath Project. But this revolution has largely not emerged at scale, mostly because deeper inefficiencies in how we organize science (e.g., career incentives) remain a bottleneck. There is even evidence that online journals actually narrowed what researchers read and cite, because scientists search or follow hyperlinks rather than browsing journals, thus potentially accelerating consensus rather than expanding the space of ideas explored.
AI could repeat this pattern at a larger scale — generating faster results within the existing paradigm, while the structural conditions for disruptive science remain unchanged or worsen. There is no reason to expect this design problem to sort itself out on its own. But if we treat AI for disruptive science as a deliberate research program, we have a better chance of building the capabilities that paradigm shifts require. And to do that, we will have to understand how to design science itself.
{{divider}}
Alvin Djajadikerta is the CEO of Evidentia Labs and a founding researcher at Science Works. He holds a PhD in Molecular Neuroscience from the University of Cambridge.
Cite: Djajadikerta, Alvin. “Designing AI for Disruptive Science.” Asimov Press (2026). DOI: 10.62211/29ej-27et
Header image by Ella Watkins-Dulaney.